An Analysis of DeepSeek-R1
An Analysis of DeepSeek-R1, DeepSeek's R1 reasoning model has been all over the news since its release, it's performance and cost are all cool but, how does it work? why is it able to compete with OpenAI's O1 while being so much cheaper?

DeepSeek's R1 reasoning model has been all over the news since its release, it's performance and cost are all cool but, how does it work? why is it able to compete with OpenAI's O1 while being so much cheaper?
These are questions I personally had in mind so here we are!
DISCLAIMER: Some parts will be simplified to make it more digestible, sources will be cited throughout the article and at the bottom if you want more in depth technicals
Model Architecture
DeepSeek's R1 utilizes a 671B Mixture of Experts (MoE) with 37B active parameter architecture.
What is MoE? What are "active parameters?"
Mixture of Experts is a Large Language Model (LLM) technique where the larger model is made up of "expert" smaller models which are good at one specific aspect of language, for instance, punctuation, verbs, visual language devices, etc.
Active parameters are the amount of a model being used while it processes input and returns output.
What does this mean?
When R1 receives input, it picks 37B parameters worth of "knowledge" that's relevant to the prompt, it then uses these to produce the output. This means that R1 has the knowledge base of 671 billion parameters (a lot) while having the speed of much smaller 37 billion parameter models. It also allows for more accurate outputs due to only relevant parameters being selected.
Now that we understand the model architecture, lets dive into the training methods DeepSeek used on R1!
Training Large Language Models
What is RL and SFT?
Reinforcement learning & Supervised fine tuning are two types of training methods used in LLMs which both have their Pros and Cons.
Reinforced Learning (RL)
RL works by letting models process data, then providing feedback in the form of rewards and penalties. Trainers will often run this process in parallel, then take the best performing models and forward them through the process. DeepSeek specifically used Chain of Thought (CoT) examples in order to produce the type of reasoning we can observe when running R1. (see image one for examples of CoT prompts).

This type of training allows outputted models to learn vast general reasoning and logic, as well as decreasing the amount of hallucinations by having the model "think" about a prompt, allowing it to break inputs down into potential requirements while retrieving relevant data from its existing knowledge base, similar to how humans process inputs and outputs.
Supervised Fine Tuning (SFT)
SFT uses pretrained models as a base, fine tuning them for specific tasks using niche specific datasets, this allows models to excel in specific areas they previously didn't. While fantastic for teaching models complex niches like math and coding, SFT requires significantly more data, specifically human annotated data, then RL. (see image 2 for a graphic on SFT)
How did DeepSeek train R1?
DeepSeek used a 4 step training process comprised of two RL & SFT stages to produce R1 (here is paper DeepSeek released on training R1)
Stage 1
DeepSeek v3 is used as a base, finetuned using thousands of cold start CoT examples (cold start meaning new conversations, not partially completed ones)
DeepSeek stated that readability and versatility both increased when this method was implemented.
Stage 2
Large scale RL was conducted, DeepSeek put particular focus on enhancing R1's reasoning capabilities, particularly for "reasoning intensive tasks such coding, mathematics, science and logic reasoning" - DeepSeek R1 Research Paper
During this stage, DeepSeek observed R1 mixing languages while producing outputs, particularly in prompts that involve multiple languages. DeepSeek implemented a "language consistency" reward which was calculated using the amount of target language words in the prompt.
This slightly reduced model performance but increased accuracy and readability, the language reward was combined with a reasoning accuracy reward which was applied until model reached convergence (model performance plateaus)
Stage 3
SFT was used to fine tune R1 for writing, role-playing and other general purpose tasks. The fine tuning data used was generated by sampling rejection data (failed responses) from the RL in stage 2, DeepSeek-V3 was used to help judge input.
Due to model output being chaotic and difficult to read, fine tuning data excluded CoT examples with long paragraphs, mixed languages and code blocks.
for each prompt, DeepSeek sampled multiple responses, retaining only correct ones, they collected ~600k reasoning related training samples.
For non reasoning data, such as writing, factual QA, self cognition (refer back to image 1) and translation, DeepSeek repurposed parts of the SFT dataset used to train DeepSeek-V3, collecting ~200k training samples unrelated to reasoning.
DeepSeek finetuned DeepSeek-R1 for two epochs (epochs are how many times you run a model over training data) using the curated dataset of ~800k samples.
Stage 4
To ensure that R1 aligned with human preferences when prompted, DeepSeek implemented a secondary round of RL aiming at improving helpfulness and harmlessness while also refining its reasoning capabilities.
For logical tasks, rule based rewards were used to guide its training, this includes math, coding, science, etc.
For general tasks, other reward models were implemented to increase performance.
For helpfulness, DeepSeek focused exclusively on the final summary, ensuring it provided correct and relevant responses.
For harmlessness, DeepSeek evaluated the entire response from the model, utilizing reward signals to incentivize harmless responses over harmful ones.
Summary of training
DeepSeek used their V3 model as a base, running two RL & SFT phases to increase performance in reasoning and non reasoning tasks, readability, versatility, helpfulness and harmlessness, Eventually producing DeepSeek-R1. The lack of human feedback learning, which ranks desirable behavior based on the subjective preferences of human workers, also increases model objectivity and response consistency.
Censorship
As with anything made in china, people instantly focused on R1's "censorship" on the web version. The censorship on DeepSeek's website is essentially a smaller LLM model overlaid to detect unfavorable content, then stopping generation if it detects anything. This form of censorship is extremely easy to jailbreak, this is also only present on their website & API, basic content policy exists on the model itself but that can, and has been removed with abliterated models that are COMPLETELY UNCENSORERED!
DeepSeek vs Everyone Else
Training is useless if we don't appreciate the results! How does R1 perform against the competition?
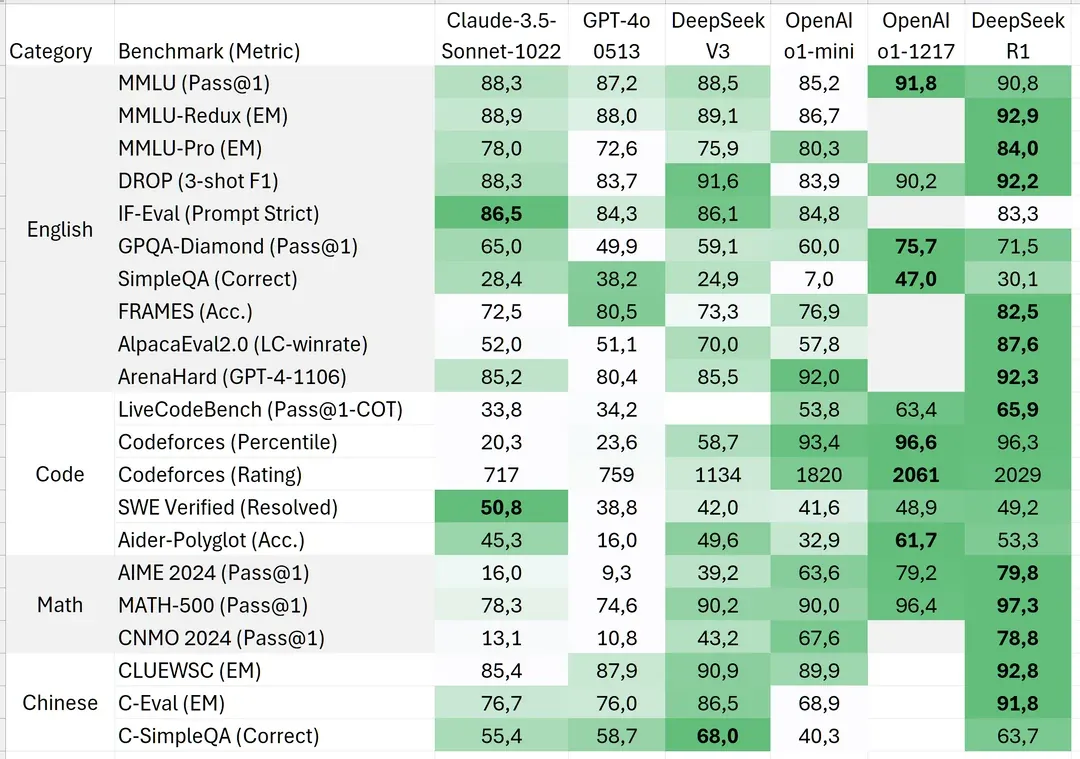
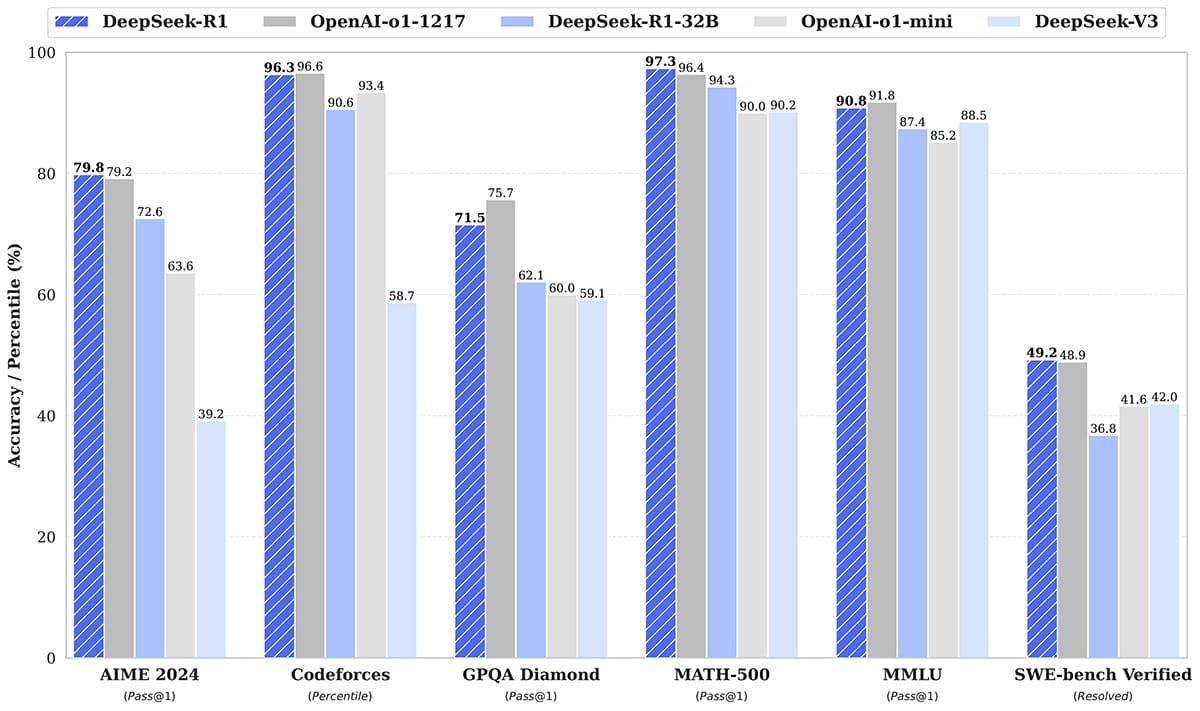
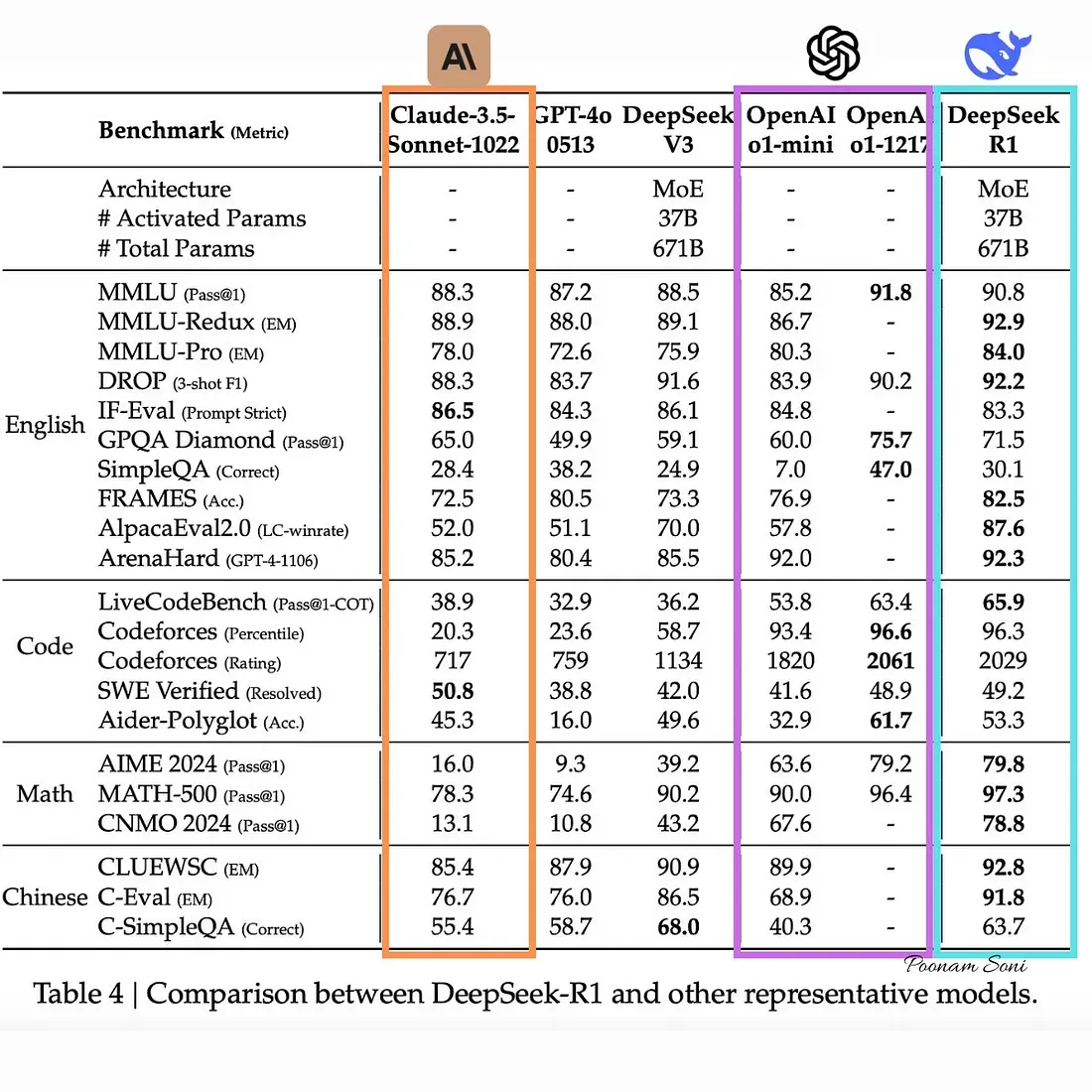

DeepSeek be crushing it! Sources: Isaak Kamau, u/balance-, HuggingFace Announcement & OpenRouter
R1 consistently performs on par or better then competing models, while having faster inference (processing speed) due to its architecture, this, by proxy, also means that token costs for R1 when used via DeepSeek's API is incredibly cheaper, anywhere from 4 to 30x cheaper depending on token usage! (the token usage shown above was with the exact same task and prompt)
Final words
DeepSeek's R1 is an incredible model, the research paper they published went into depth about the challenges they faced, their methods for overcoming them, as well as their general process for developing R1. This model has already shattered expectations and rattled the market, over 1T USD worth of market cap has been wiped from the US stock exchange due to investors losing confidence in NVIDIA & associated companies.
I cannot wait to see what DeepSeek produces next, or what other fun surprises the AI industry still has in store for us.
Thanks for reading! If you enjoyed this article, consider subscribing to my newsletter so you can be notified whenever I post new content! have a great day!
Bibliography
Click to expand
🚀 Introducing DeepSeek-V3. (n.d.). In DeepSeek API Docs. Retrieved January 30, 2025, from https://api-docs.deepseek.com/news/news1226Balance-. (2025). DeepSeek-R1 and distilled benchmarks color coded. https://www.reddit.com/r/LocalLLaMA/comments/1i5q6b9/deepseekr1_and_distilled_benchmarks_color_coded
DeepSeek R1: All you need to know 🐳. (n.d.). In DeepSeek R1: All you need to know 🐳. Retrieved January 30, 2025, from https://fireworks.ai/blog/deepseek-r1-deepdive
deepseek-ai. (n.d.). DeepSeek-R1/DeepSeek_R1.pdf at main · deepseek-ai/DeepSeek-R1. In GitHub. GitHub. Retrieved January 30, 2025, from https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
deepseek-ai/DeepSeek-R1 - Demo - DeepInfra. (n.d.). In Deep Infra. Retrieved January 30, 2025, from https://deepinfra.com/deepseek-ai/DeepSeek-R1
Kamau, I. (2025). A Simple Guide to DeepSeek R1: Architecture, Training, Local Deployment, and Hardware Requirements. In Medium. Medium. https://medium.com/@isaakmwangi2018/a-simple-guide-to-deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-300c87991126
Maarten Grootendorst. (n.d.). A Visual Guide to Mixture of Experts (MoE). In newsletter.maartengrootendorst.com. Retrieved January 30, 2025, from https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
PromptHub Blog: Chain of Thought Prompting Guide. (n.d.). In www.prompthub.us. Retrieved January 30, 2025, from https://www.prompthub.us/blog/chain-of-thought-prompting-guide
README.md · deepseek-ai/DeepSeek-R1 at main. (2025). In huggingface.co. https://huggingface.co/deepseek-ai/DeepSeek-R1/blob/main/README.md